Web App Development Challenges
Frameworks, Libraries, Standards
Need of Componentization
Web Components
Polymer
React.js
Angular.js
Why not jQuery?
Other Options
Different Mental Model
Putting It All Together
Summary
Links
Web App Development Challenges
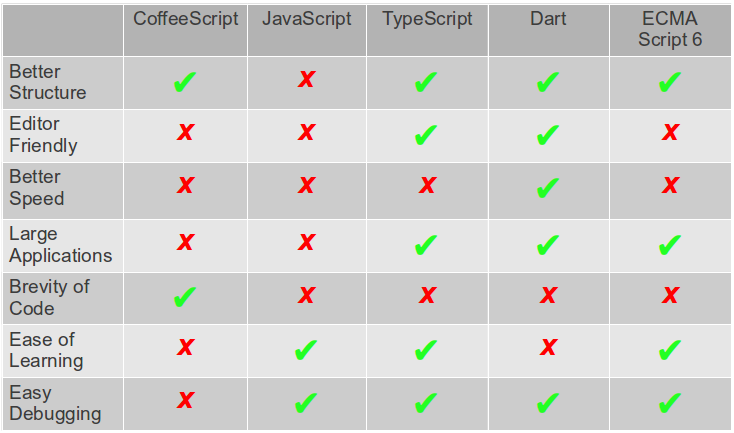
Web applications become larger, more sophisticated and virtually indistinguishable from desktop apps. This leads to more JavaScript, markup and styles being used. In “JavaScript and Friends: CoffeeScript, Dart and TypeScript” we discussed how JavaScript is adapting to this trend and what alternative languages started to appear that try to address some of the major pain points.
There are multiple challenges in developing large modern Web apps, some of them are listed below.
- Maintainability
It should be relatively easy to find a piece of code responsible for a certain part of the app. Ideally, this piece of code should encapsulate some of the implementation details of that part and be simple enough to understand and modify it without introducing any bugs.
-
Testability
It should be easy to instantiate pieces of code comprising the app and verify their behavior in a test environment. We would also like to test how those pieces interact with each other and not just that every one of them works properly on its own.
-
Code reuse
If in different places of the application there are similar UI elements or functionality (such as, for example, dialogs) it should be possible to reuse the same code, including markup and styles, across the app in all such places.
-
View updates
When the data being presented on the UI as part of some view is modified, the corresponding view needs to be re-rendered. We should be smart and re-render only those parts of the app that really need it in order to avoid loosing the visual context after a potentially quite costly complete re-render.
These and other challenges are more or less successfully resolved by various libraries and frameworks or combinations of them. One notable example many are familiar with is Angular, which to certain extent addresses them all.
However, in this post we are not going to discuss all the intricate details of frameworks like Angular, partly because they offer much more than just componentization and code reuse, and partly in order to stay a bit more focused. Neither are we really going to particularly discuss other challenges besides componentization as every one of them would probably merit a separate blog post. For example, it is more or less established that some form of MVC (MVV, MVP, etc.) can help with maintainability and view updates, but we will discuss it here only partially. Fully covering the outlined challenges and different approaches to address them will probably lead to a medium-sized book on developing Web applications and this is definitely not what we are after in this article.
So we will try to stay focused on one particular topic: componentization and discuss some of the philosophy and ideas that various frameworks and libraries exhibit in this particular area, but which are unfortunately still quite often lost behind the intricate technical details of the APIs they expose or are not emphasized enough and underutilized by developers. For example, I saw at least a few Angular projects that did not reuse as much code as they could have just because for some reason they avoided using custom directives (a bit later we will discuss how those relate to Web Components). After reading this article hopefully you will have a better grasp of the subject and also understand that despite superficial differences between APIs some common principles behind are still quite similar.
Frameworks, Libraries, Standards
In this post we will be talking about, looking into the technical details and comparing Web Components, Polymer, React.js and Angular.js in order to see how they relate to each other in regards to componentization, and what similarities and differences there are. But before we can do that, let’s first establish some initial relationship between these technologies and briefly explain what every one of them is and is not. This will a bit simplify further reading.
- Web Components http://webcomponents.org/
Is just a set of standards that facilitate development of reusable components and should be natively supported by browsers. The level of support is different depending on the browser. This is not a library or framework.
-
React https://facebook.github.io/react/
Is a functional-style “view” library for feeding data into a tree of React components and rendering this tree into HTML. This is not a framework as React does not suggest a predefined way of creating a web app and just deals with the view part. In fact, you can use React with other frameworks, but the most canonical way suggested by Facebook would be to use it in a Flux architecture.
-
Polymer https://www.polymer-project.org/
Is a polyfill library to bring Web Components standards to different browsers that do not support them natively yet. In addition to implementing the current version of the standards Polymer adds a few things of its own that are not yet in the standards and may be even never included there. So we can say that Polymer is a library based on the Web Components standards, but like React it is also not a framework.
-
Angular https://angularjs.org/
Unlike the previous three, this is a true opinionated framework that to a large extent dictates (for better or for worse, depends on your viewpoint) how a Web app should be structured and in what exact way certain things should be done. There is still some flexibility but most of the time you just should do things Angular way. It also allows to create reusable components, but those components will be reusable only in another Angular app (like those made with React will be reusable only in React apps, more discussion on the topic of interoperability later in the article).
Of course we can cover other frameworks and libraries and even venture to create some site similar to http://todomvc.com/, this time not for comparing the MVC implementations but support for componentization. If somebody would like to create such a site, feel free to fork and extend the repository with examples from the present article https://github.com/antivanov/ui-components as a good starting point. We will, however, focus only on those libraries/frameworks listed above as a few different examples should already give a good feeling of the way things can be done and we can already have some meaningful discussion and comparison.
Need of Componentization
So why do we need componentization?
You might have heard about domain-specific languages (DSLs) http://martinfowler.com/books/dsl.html and such before in other areas of software development, not necessarily front-end or Web. In brief, the main idea is that in order to solve some challenging problem it often pays off to first create a language in which this problem is easily solvable. Then having this language allows you to describe the system and its behavior much easier. One good example of a DSL is SQL query language that provides a convenient way to manipulate and query data stored in a relational database. If we try to do such data manipulation and queries in plain code we mignt end up in a world of pain and maintainability nightmare if our data schema and queries are complex enough. And SQL just allows us to express what we want to do with data in a very succinct and declarative fashion.
The idea is that, as Web applications become more complex, they are in many respects not that different from other applications and can certainly benefit from creating DSLs. In fact HTML is already such a DSL, albeit quite a low level and general purpose one. Of course, HTML5 introduces some new semantic tags such as <section>, <header>, <footer>, etc. but this is still not high enough level of abstraction if you develop a large app. What we would probably like to have is to operate with more high level things, in the case of a Web store this might be: <cart>, <searchbox>, <recommendation>, <price>, etc. It looks like it can be nice and beneficial to be able to extend the default HTML vocabulary.
Naturally, if your app is quite simple and is just a couple of simple pages you may not need componentization, abstraction and code reuse so much. Compare this to the case when you need to write some simple script in, say, Python, then you may not need to define any classes or even functions in that script. But still, it is nice to have the ability to create reusable abstractions (functions, classes) when there is a genuine need for them. Components in a Web app are not all that different from functions or classes in many programming languages in this regard.
The obvious benefits of creating and using components are better maintainability, code reuse and speed of development once you have a comprehensive set of components developed for your app. Components are like building blocks from which you can build your apps. If those blocks are well-designed, you can just quickly throw together some functionality that before would require a lot of tedious boiler-plate coding and repetition. Same as with functions and classes, but just on a bit different level.
Hopefully, by now you are becoming convinced (if you were not before) in the potential usefulness of components and would like to know more about the technical details. So far our discussion has been a bit abstract and philosophical, so it is right about time to delve into examples and see how this all is implemented in practice.
Examples
We chose to implement a simple Breadcrumbs component using different technologies listed above, the demo is available at http://antivanov.github.io/ui-components
The source code can be found at https://github.com/antivanov/ui-components, feel free to check it out, fork it and maybe suggest some improvements, just create a pull request.
In the next few sections we will delve deeper into various frameworks and libraries and will explain some of the code in the examples.
Web Components
We will start with Web Components, a set of evolving standards and best practices that allow to create and use custom HTML elements. First, let’s quickly go over some of the standards. The example code https://github.com/antivanov/ui-components/tree/master/WebComponents/breadcrumbs
HTML imports
Allows to include HTML documents into other HTML documents. In our example we include breadcrumbs.html into breadcrumbs.demo.html by inserting the following import into the latter:
<link rel="import" href="breadcrumbs.html">
That’s pretty much all there is to it. There are, of course, some further details such as how we avoid including the same file twice, detecting circular references, etc. you can read more here http://webcomponents.org/articles/introduction-to-html-imports/
Custom elements
Our Breadcrumbs component is implemented as a custom HTML element, that we register as follows:
document.registerElement('comp-breadcrumbs', {
prototype: prototype
});
where prototype is some object which defines what methods and fields will be available on a Breadcrumbs instance that we create like this:
var breadcrumbsElement = document.createElement('comp-breadcrumbs');
We also could have just used this new custom element in the HTML markup and it would have been instantiated just like the rest of the HTML elements, more examples http://webcomponents.org/tags/custom-elements/
Shadow DOM
Custom element can have shadow DOM associated with it. The elements belonging to this shadow DOM are encapsulated inside this custom element, are hidden and considered to be the implementation details of the element. Some predefined HTML elements have shadow DOM as well, for example <video>. When we want to specify that Breadcrumbs element should have some shadow DOM associated with it, we create a shadow root and add some DOM element to it:
this.createShadowRoot().appendChild(element);
Shadow DOM allows to avoid revealing component implementation details on the HTML level to other components and client code using this component. This results in the HTML being more modular and high level. More on Shadow DOM http://webcomponents.org/articles/introduction-to-shadow-dom/
HTML templates
Finally it is possible to use templates, a special <template> tag is introduced for this purpose. In our example in breadcrumbs.html:
<template id="breadcrumbs-template">
<style>
...
.crumb {
border: 1px solid transparent;
border-radius: 4px;
}
...
</style>
<div class="breadcrumbs">
</div>
</template>
Our template also includes some styling information that will be applied only to the HTML created from this template. In this manner templates also enable hiding CSS implementation details and provide for better encapsulation of styles.
The contents of the template are not active until HTML has been generated from this template: images will not be fetched, scripts will not be executed, etc.
There is no data binding support, template is just a piece of static HTML.
In order to create an element from template, we first should import template DOM node into the current document:
var element = document.importNode(template.content, true);
More details http://webcomponents.org/articles/introduction-to-template-element/
Breadcrumbs example
The Breadcrumbs example demonstrates how these different standards can be used together to create a reusable component which, as we noted, will be implemented as a custom element. Let’s look at the code of breadcrumbs.html:
<template id="breadcrumbs-template">
<style>
.crumb,
.crumb-separator {
padding: 4px;
cursor: default;
}
.crumb {
border: 1px solid transparent;
border-radius: 4px;
}
.crumb:hover,
.crumb:focus {
background-color: #f2f2f2;
border: 1px solid #d4d4d4;
}
.crumb:active {
background-color: #e9e9e9;
border: 1px solid #d4d4d4;
}
.crumb:last-child {
background-color: #d4d4d4;
border: 1px solid #d4d4d4;
}
</style>
<div class="breadcrumbs">
</div>
</template>
<script>
(function() {
function activateCrumb(self, crumb) {
var idx = parseInt(crumb.getAttribute('idx'));
var newPath = self.path.slice(0, idx + 1);
if (newPath.join('/') != self.path.join('/')) {
var event = new CustomEvent('pathChange', {
'detail': newPath
});
self.dispatchEvent(event);
}
}
function renderPath(self, path) {
var maxEntries = parseInt(self.getAttribute('maxEntries')) || -1;
var renderedDotsSeparator = false;
while(self.container.firstChild) {
self.container.removeChild(self.container.firstChild);
}
path.forEach(function(pathPart, idx) {
//Skip path entries in the middle
if ((maxEntries >= 1) && (idx >= maxEntries - 1)
&& (idx < path.length - 1)) {
//Render the dots separator once
if (!renderedDotsSeparator) {
self.container.appendChild(
createDotsSeparator(path, maxEntries)
);
self.container.appendChild(createCrumbSeparator());
renderedDotsSeparator = true;
}
return;
}
self.container.appendChild(createCrumb(pathPart, idx));
if (idx != path.length - 1) {
self.container.appendChild(createCrumbSeparator());
}
});
}
function createDotsSeparator(path, maxEntries) {
var crumbSeparator = document.createElement('span');
var tooltipParts = path.slice(maxEntries - 1);
tooltipParts.pop();
var tooltip = tooltipParts.join(' > ');
crumbSeparator.appendChild(document.createTextNode('...'));
crumbSeparator.setAttribute('class', 'crumb-separator');
crumbSeparator.setAttribute('title', tooltip);
return crumbSeparator;
}
function createCrumb(pathPart, idx) {
var crumb = document.createElement('span');
crumb.setAttribute('class', 'crumb');
crumb.setAttribute('tabindex', '0');
crumb.setAttribute('idx', idx);
crumb.appendChild(document.createTextNode(pathPart));
return crumb;
}
function createCrumbSeparator() {
var crumbSeparator = document.createElement('span');
crumbSeparator.appendChild(document.createTextNode('>'));
crumbSeparator.setAttribute('class', 'crumb-separator');
return crumbSeparator;
}
var ownerDocument = document.currentScript.ownerDocument;
var template = ownerDocument.querySelector('#breadcrumbs-template');
var prototype = Object.create(HTMLElement.prototype);
prototype.createdCallback = function() {
var self = this;
var element = document.importNode(template.content, true);
//Current path
this.path = [];
//Crumbs container
this.container = element.querySelector('.breadcrumbs');
this.container.addEventListener('click', function(event) {
if (event.target.getAttribute('class') === 'crumb') {
activateCrumb(self, event.target);
}
}, false);
this.container.addEventListener('keypress', function(event) {
if ((event.target.getAttribute('class') === 'crumb')
&& (event.which == 13)) {
activateCrumb(self, event.target);
}
}, false);
this.createShadowRoot().appendChild(element);
};
prototype.setPath = function(path) {
this.path = path;
renderPath(this, path);
};
document.registerElement('comp-breadcrumbs', {
prototype: prototype
});
})();
</script>
In lines 1-28 we define the template and CSS styles that will be used for the component. The JavaScript code of the component is contained inside the <script> tags and we register the custom element comp-breadcrumbs in lines 137-139. During registration as an argument we pass a prototype object that contains fields and methods that will be attached to a new element instance once it is created. Let’s go over these methods in more detail.
133-136 the component exposes method setPath that can be called by the client code directly on the DOM comp-breadcrumbs element. Here we just remember the path passed as an argument and re-render the component.
107-132 is the most interesting part as we define the createdCallback which is a predefined hook method that is called when a custom element is created. In lines 107-108 we do some hoops to get to the template we just defined, it is a bit tricky to do since the current document when we load breadcrumbs.html is a different document: breadcrumbs.demo.html. In 109 we inherit from HTMLElement. 113 import the node to the current document and in line 131 create shadow root and add the imported template to it. The lines 116-130 attach some listeners and define initial values for fields.
44-105 deal with rendering the current path as a set of crumbs, crumb separators and dots to the shadow DOM of the current instance of comp-breadcrumbs. Here we do not use any libraries like jQuery which might have shortened some of the DOM element creation boilerplate. In line 45 we check the value of the maxEntries attribute and if it is set we make sure that we render dots instead of extra breadcrumbs.
Note how we have to handle data-binding all by ourselves and make sure that the changes in the state of the component are properly reflected in the generated HTML (view). This feels a bit low-level and tedious, certainly we could use some library or framework for this task, but more on this later.
32-42 we define a handler which is triggered whenever a particular crumb is activated, either by clicking on it or pressing Enter. In lines 37-40 we create and dispatch custom pathChange event so that the client code can listen for this event and act accordingly, for example, in response navigate to a certain page inside the app.
A very nice thing is that with our new custom element we can just use all the familiar DOM APIs and the event system we already know: getAttribute, createElement, querySelector, addEventListener, etc. will just work like with other non-custom HTML elements. Also all the nuances of custom element implementation are well-hidden from its users and they can deal with the component as if it were just like any other normal DOM element, which provides for excellent encapsulation and does not lock us into using some particular library or framework together with our custom elements.
How to use in your project
Some browsers do not yet support all of these standards and although Web Components is definitely the future way of creating reusable components, while it still evolves and is being adopted you have to use something else. The first closest option to consider is Polymer, a library that brings Web Components support to all browsers and adds some of its own features on top. Arguably even in the future when all browsers support Web Components and the standards have matured a lot, you will still have to use some higher level library, because standards tend to stay quite generic and low level in order not to overburden the browser developers with more features to support and also leave some flexibility for library developers.
Polymer
One library you may use to add Web Components support to your apps is Polymer https://www.polymer-project.org. It enables Web Components for browsers that do not yet support corresponding standards. For example, with minimal changes we can make our Breadcrumbs custom element work in Firefox just like in the previous example it used to work in Chrome. However, some things will still not work quite the way we would like them to. For example, since there is no shadow DOM implementation yet in Firefox the DOM elements generated by our custom element will be added directly to the DOM and will not be hidden from the client code. The example http://antivanov.github.io/ui-components/Polymer/breadcrumbs/breadcrumbs.demo.html, source code https://github.com/antivanov/ui-components/blob/master/Polymer/breadcrumbs/breadcrumbs.standard.only.html
Let’s quickly go over a few changes we have to make. The parts common with the Web Components example are omitted for brevity’s sake:
<link rel="import" href="../bower_components/polymer/polymer.html">
<polymer-element name="comp-breadcrumbs" tabindex="0">
<template id="breadcrumbs-template">
<style>
...
.crumb {
border: 1px solid transparent;
border-radius: 4px;
}
...
</style>
<div class="breadcrumbs">
</div>
</template>
<script>
(function() {
...
var prototype = {};
prototype.path = [];
prototype.domReady = function() {
var self = this;
//Crumbs container
this.container = this.shadowRoot.querySelector('.breadcrumbs');
this.container.addEventListener('click', function(event) {
if (event.target.getAttribute('class') === 'crumb') {
activateCrumb(self, event.target);
}
}, false);
this.container.addEventListener('keypress', function(event) {
if ((event.target.getAttribute('class') === 'crumb')
&& (event.which == 13)) {
activateCrumb(self, event.target);
}
}, false);
renderPath(this, this.path);
};
...
Polymer('comp-breadcrumbs', prototype);
})();
</script>
</polymer-element>
In line 1 we import the Polymer library using familiar HTML import feature. First difference with the pure Web Components example is noticable in the lines 3 and 46: we wrap the <script> and <template> definitions inside <polymer-element> for which we also specify tabindex attribute so that our custom element can be focused from keyboard using the Tab key.
In line 20 the prototype of the custom element is just an empty object and we do not have to inherit from HTMLElement like before.
We cannot create a real shadow root in many browsers so the Polymer API differs here as well. In line 27 we just query for a fake “shadow root” and at this point our template has already been rendered and the resulting DOM element appended to that root.
Finally in line 43 we register our new custom element with Polymer which also differs from the standard way of doing this.
Besides support for Web Components standards, which are pretty low-level and generic, Polymer also brings in some of its own higher-level features that might make it worth using it even when Web Components support becomes very mainstream and common.
To illustrate some of those features let’s quickly go over another example that also deals with the Breadcrumbs component but uses some Polymer-specific features https://github.com/antivanov/ui-components/blob/master/Polymer/breadcrumbs/breadcrumbs.html Most interesting parts are, as before, where the example differs from the previous one:
<link rel="import" href="../bower_components/polymer/polymer.html">
<polymer-element name="comp-breadcrumbs">
<template id="breadcrumbs-template">
<style>
...
</style>
<div class="breadcrumbs" on-keypress="{{_onKeypress}}">
<template id="crumbs" repeat="{{crumb, index in crumbs}}">
<span class="{{crumb.dots ? 'crumb-separator' : 'crumb'}}"
idx="{{crumb.idx}}" title="{{crumb.tooltip}}"
on-click="{{_onActivateCrumb}}"
tabIndex="0" >{{crumb.value}}</span>
<span class="crumb-separator">></span>
</template>
</div>
</template>
<script>
(function() {
...
var prototype = {};
prototype.path = [];
prototype.crumbs = [];
prototype.setPath = function(path) {
this.path = path;
this.crumbs = renderPath(this, path);
};
...
Polymer('comp-breadcrumbs', prototype);
})();
</script>
</polymer-element>
As can be seen the templating features of Polymer are more advanced than the standard ones Web Components have to offer. For example, in lines 9 and 13 we can bind event handlers to the HTML generated from the template directly in the template code.
Polymer templates are also automatically bound to the state of the current component, for example, see line 14 where we refer to crumb.value pretty much like we would do if we used some template system like Mustache https://github.com/janl/mustache.js
Line 10 demonstrates how we can iterate over model with repeat when generating repetitive HTML markup. Also a very nice feature that saves our effort from doing the same thing in JavaScript on our own as we saw in the previous example.
More information about Polymer templating https://www.polymer-project.org/0.5/docs/polymer/template.html
Another useful thing provided by Polymer, which is not shown in this simple example, is that it exposes in the form of components (well, what else can we expect?) quite a lot of useful functionality that we can reuse when developing our own components. One example of such an useful component made available to us by Polymer is core-ajax https://www.polymer-project.org/0.5/docs/elements/core-ajax.html
And note, for example, how this Progress bar implementation easily extends the core-range component https://github.com/Polymer/paper-progress/blob/master/paper-progress.html All we need to do to take advantage of an already existing Polymer component that we might need, is to include the corresponding extends attribute to the Polymer component declaration as described in the documentation https://www.polymer-project.org/0.5/docs/polymer/polymer.html#extending-other-elements
Existing component libraries
There are quite a few components (called “elements” in the Polymer terminology) developed with Polymer by somebody else that you can consider using on your own project. For example, take a look at http://customelements.io where everybody can publish their components. In addition to that Polymer itself provides quite a few ready to use components right out of the box such as the ones that can be found here https://www.polymer-project.org/0.5/docs/elements/material.html
React.js
While the Web Components standards are still evolving, some libraries try to solve the problem of componentization and code reuse in Web apps in their own way.
One such library is React https://facebook.github.io/react/ Besides support for building reusable components it also tries to solve the view update problem: “React implements one-way reactive data flow which reduces boilerplate and is easier to reason about than traditional data binding”.
We will try to explain how React works, but, if you wish to read more, just feel free to first read the tutorial https://facebook.github.io/react/docs/tutorial.html
Authors of React.js have made a few architectural choices that set it apart from other approaches we are discussing in this article.
First, everything is a component, and to build an app one actually has to first think about how to split the app into components, and then how to compose and nest them. This is quite different from using Web Components where you can just optionally define components if you wish to do so, but you can also use whatever low level HTML and JavaScript you wish together with it. In our React example, even the demo app that uses the Breadcrumbs component is a separate component https://github.com/antivanov/ui-components/blob/master/React.js/breadcrumbs/breadcrumbs.demo.js:
How to define a component, rendering, events, properties and state
var BreadcrumbsDemo = React.createClass({
getContent: function(path) {
return path[path.length - 1];
},
getInitialState: function() {
return {
path: this.props.path
};
},
onPathChange: function(value) {
this.setState({
path: value
});
},
reset: function() {
this.setState({
path: this.props.path
});
},
render: function() {
return (
<div>
<div id="breadcrumb-container">
<Breadcrumbs path={this.state.path} maxEntries="5"
onChange={this.onPathChange}/>
</div>
<div id="content">{this.getContent(this.state.path)}</div>
<button id="resetButton" onClick={this.reset}>Reset</button>
</div>
)
}
});
var fullPath = ['element1', 'element2', 'element3', 'element4',
'element5', 'element6', 'element7'];
React.render(
<BreadcrumbsDemo path={fullPath}/>,
document.querySelector('#container')
);
The most important part of a component definition is method render in lines 20-31 where the component declaratibely defines how it should be rendered. This can include other components like Breadcrumbs in line 24 and familiar HTML elements like div in line 27.
We can also parameterize the rendition with the component data which can come from two sources: component state and component properties.
Properties of a component should be considered immutable and are passed from a parent component via attributes, like it is done in the line 38 where we pass fullPath to be used with our Breadcrumbs component in the demo. Every component has a parent or is a root-level component like our BreadcrumbsDemo component.
State of a component is something than can be changed during the component lifecycle. Looks like this is a necessary compromise in the design of React to still be able to do local changes to a component without propagating them all the way from the root of the app. However, beware of the state, it should be used very sparingly, and if something can be a property and used by several nested or sibling components, make it an immutable property. Method getInitialState in lines 5-8 is used to define what should be the default initial state of BreadcrumbsDemo. State can be accessed like is demonstrated in line 27 via the state property on the instance of the current component. Setting state is also simple, you just need to call the setState method as it is shown in lines 16-18.
Whenever the state or properties of the current component are changed and they are used in the component rendition, React will re-render component. This is how the view update development challenge is solved by React: it will update the view automatically once you declaratively described in the render method how it should be done.
In fact, since just re-rendering the whole page because of one value update is costly and inefficient, React is very smart about updating only those parts of the page that need to be updated, which is completely hidden from us as developers and is one of the core and most beautiful features of React.
So, in lines 24-25 we create a Breadcrumbs component and pass it this.state.path as the path property which will be accessible in a Breadcrumbs instance via this.props.path.
React components can use special XML-like JavaScript syntax extension for defining what they are rendered to. This extension is called JSX http://facebook.github.io/jsx/ and we just saw what it looks like in lines 22-29 and 38 where we defined a couple of JSX templates.
What about event handling and interactivity? In line 25 we define the onChange attribute, which is part of the Breadcrumbs component public API. Whenever the path changes, the event handler onPathChange from lines 10-14 will be called. In line 28 we define the onClick handler as this.reset so that when the button is clicked we reset the component state in lines 15-19.
You may remember from before that using inline event handlers and having attributes like onClick is considered a bad practice when creating HTML markup, but let’s not rush with any conclusions about React yet. Here it is different since what we are defining in a JSX template is not HTML although it looks a lot like it. Instead, internally, React will create from this template a tree of components, so called virtual DOM, will take care of event handling optimization and use event delegation when needed, and the generated HTML will not contain any inline event handlers. So in the context of React inline event handlers are just the way to go. And the div from line 27 is not actually an HTML element, but a template based on which a React div component will be created in virtual DOM, and this component will then be rendered as an HTML div in real DOM.
Note, how we have two parallel structures that coexist in a React application: real DOM which is what we are used to and virtual DOM, which is a tree of React components. React takes care of rendering the virtual DOM into real DOM and making sure those are in sync with each other.
Going back to Web Components, let’s recall the shadow DOM concept. For Web Components the component tree is in real DOM and implementation details of components such as video are hidden in the shadow DOM pieces attached to real DOM. For React real DOM plays the role of shadow DOM and the component tree, virtual DOM, is just a tree of React components stored in memory. So here we can clearly see certain parallels between Web Components and React.
Breadcrumbs example
Now that we have a better understanding of inner workings of React.js apps let’s revisit our Breadcrumbs example ported to React https://github.com/antivanov/ui-components/blob/master/React.js/breadcrumbs/breadcrumbs.js
First thing we see is how our component is now composed from other components: Crumb and CrumbSeparator. For example we can have a structure like this:
- Breadcrumbs
- Crumb
- CrumbSeparator
- Crumb
- CrumbSeparator
- Crumb
In other words, Breadcrumbs is just a sequence of interleaving Crumb and CrumbSeparator components. So in a way it is a more formal definition of what a Breadcrumbs is and is much closer to how we perceive it in the app.
var Crumb = React.createClass({
activate: function() {
this.props.onSelected(this.props.idx);
},
onKeyPress: function(event) {
if (event.nativeEvent.which == 13) {
this.activate();
}
},
render: function() {
return (
<span className="crumb" tabIndex="0" onKeyPress={this.onKeyPress}
onClick={this.activate}>{this.props.value}</span>
)
}
});
var CrumbSeparator = React.createClass({
render: function() {
return (
<span className="crumb-separator"
title={this.props.tooltip}>{this.props.value}</span>
)
}
});
var Breadcrumbs = React.createClass({
onSelected: function(idx) {
if (idx < 0) {
return;
}
var newPath = this.props.path.slice(0, idx + 1);
if (newPath.join('/') != this.props.path.join('/')) {
this.props.onChange(newPath);
}
},
render: function() {
var self = this;
var path = this.props.path;
var maxEntries = this.props.maxEntries || -1;
var hasShortened = false;
var crumbs = [];
path.forEach(function(pathPart, idx) {
//Skip path entries in the middle
if ((maxEntries >= 1) && (idx >= maxEntries - 1)
&& (idx < path.length - 1)) {
//Render the dots separator once
if (!hasShortened) {
var tooltipParts = path.slice(maxEntries - 1);
tooltipParts.pop();
crumbs.push(
<CrumbSeparator value="..." key={idx}
tooltip={tooltipParts.join(' > ')}/>,
<CrumbSeparator value=">" key={path.length + idx}/>
);
hasShortened = true;
}
return;
}
crumbs.push(
<Crumb idx={idx} value={pathPart} key={idx}
onSelected={self.onSelected}/>
);
if (idx != path.length - 1) {
crumbs.push(
<CrumbSeparator value=">" key={path.length + idx}/>
);
}
});
return (
<div className="breadcrumbs">
{crumbs}
</div>
);
}
});
CrumbSeparator component in lines 18-25 is quite simple, it does not have any interactivity and just renders into a span with a supplied tooltip and text content.
Crumb in lines 1-16 has some handling for key presses and clicks. In lines 2-4 we call the function this.props.onSelected with the index of the current crumb this.props.idx, both properties have been supplied by the parent Breadcrumbs components in the lines 66-67.
The Crumb and CrumbSeparator components are quite self-contained and simple, yet they hide some of the low-level details from the Breadcrumbs implementation and can be easily composed into a Breadcrumbs component.
In line 67 we specify that onSelected function from lines 28-37 should be called whenever a Crumb child component is selected. In onSelected we just check if the path has changed compared to what Breadcrumbs received in its properties in line 34, and then call the supplied onChange handler in line 35. As you might remember we defined this handler as a property on the current Breadcrumbs instance earlier in BreadcrumbsDemo.
Then the implementation of the render function in lines 38-80 repeats the logic we already saw in earlier examples for Polymer and Web Components. We can construct the JSX template dynamically in lines 66-67, 70-71 and inline parts of it later in line 78. Lines 48-64 deal with the case when the Breadcrumbs component has a specified maxEntries property.
Note, how the example is simpler and cleaner than what we did before even with Polymer. This is because quite many low-level details such as rendering templates and binding data to the views are done for us by React which seems to be a nice bonus to componentization we get.
Key points, philosophy behind React.js
Let’s outline some of the keypoints that the example above demonstrates, we will re-iterate some of them a bit later when we discuss how different componentization approaches relate to each other.
React is a view only library that solves the challenge of binding data to view and creating reusable components. Data is transformed by React into a component tree and then this tree is transformed into HTML.
Every React component can be viewed as a function that takes some arguments via its properties and returns (from the render method) a new value that can include some other React components or React equivalents of HTML elements such as <div>.
Composing your app from React components is quite similar to composing a program from functions. React encourages a functional style where component definitions are declarative and handles the low-level details of how to make this functional definition of an app work efficiently. Feel free to read more about functional programming http://en.wikipedia.org/wiki/Functional_programming
When looking at React one can clearly see certain similarities with a domain specific language for solving a specific problem created in Lisp http://en.wikipedia.org/wiki/Lisp_%28programming_language%29. Just the brackets are a bit different, instead of () it is <> and React is not a general purpose language, but just a view library.
As JavaScript was in part inspired by Scheme (dialect of Lisp) http://en.wikipedia.org/wiki/Scheme_%28programming_language%29 and gives a lot of attention and flexibility to functions, React feels quite natural to use and is following the underlying language philosophy in this regard.
It is very easy to compose and nest functions in JavaScript, and so it is easy to compose and nest components in React. React does not try to redefine JavaScript or impose its own vision of the language like Angular to some extent does as we will see in the next section.
But JavaScript is not quite a functional language unlike, for example, Haskell, due to the presence of mutable shared state, so we have to take extra measures when using React to make sure that we do not modify things such as component properties, and more development discipline and effort is required in this respect than if React were to use a real functional language.
React provides a declarative, functional and powerful mechanism of composition and abstraction and is conceptually quite simple because of this.
One minus is that React is non-standard, does things in its own way, and the components we create will be reusable only in React apps. Although React is much less intrusive than, say, Angular and does not dictate how the whole app should be structured. Instead it focuses on only a few things: componentization and view updates.
Another minor minus is that CSS is still not modular, and unlike in Web Components, styles live completely separately from the JavaScript part of the app.
Flux
In addition to the view part represented by React, one can also choose to follow the default app arhitecture recommended for it. This architecture is called Flux https://facebook.github.io/flux/ and ensures that the data flows to your React components in an organized manner via one control point. React itself just defines how data should be transformed into HTML, and does not say much about what should be the data lifecycle in the app, Flux tries to complement this gap. But, of course, you can also choose any MVC framework you like and use it with React.
Existing component libraries
You can search for React components here http://react-components.com/ or use React Bootstrap http://react-bootstrap.github.io/components.html or React Material https://github.com/SanderSpies/react-material
Angular.js
Another way to solve the componentization challenge is to use Angular, a full-fledged framework for building modern Web apps. Like React it allows to easily create and compose you application from reusable components, unlike React this is not its main feature, and it is not as emphasized, you can even have an app written with Angular and no reusable components at all. Although the documentation https://angularjs.org/ explicitly states that “AngularJS lets you extend HTML vocabulary for your application.” far too many apps written with Angular that I saw completely ignore this feature, so hopefully our discussion of how and why we should create components with Angular might be useful for some Angular developers as well.
In Angular components can be defined using directives, and directives can be used not only to create components but also for many other things. We will briefly remind what directives are below. Also Angular deals with routing, data flow, has far more concepts to grasp, and has a much stronger focus on testability. Creating components and view updates is only a part of what Angular is all about, and the philosophy behind those is a bit different from what we have just discussed. Let’s quickly go over some of the Angular features that we will utilize in our example.
Directives
Directives are special markers that can be attached to HTML elements in the form of attributes or CSS classes, or they can even be HTML elements themselves. The last case is the most interesting one for us as directives in the form of HTML elements behave a lot like custom HTML elements that we already saw in Web Components. More information https://docs.angularjs.org/guide/directive
Simple example:
<body ng-app="BreadcrumbsDemo" ng-controller="Path">
Directive ng-app defines a new Angular app and the root element for it. Another directive ng-controller binds controller named Path to the part of the DOM rooted in the HTML element on which the directive is used.
Directives are a bit like annotations on DOM, they can have a meaning that we can define for them, and then Angular will interpret our directive definitions and enhance the DOM with the specified behavior and elements. There are a few predefined Angular directives, two of which we just saw in use, but also we can define our own, and, in fact, this is the mechanism we will be using to create our own custom Breadcrumbs component.
Controllers and scopes
Controller https://docs.angularjs.org/guide/controller is a piece of code that is associated with some part of HTML by using ng-controller directive. In our example https://github.com/antivanov/ui-components/blob/master/Angular.js/breadcrumbs/breadcrumbs.demo.html:
<body ng-app="BreadcrumbsDemo" ng-controller="Path">
<div id="breadcrumb-container">
<comp-breadcrumbs path="path" max-entries="5"
on-change="onPathChange(path)"></comp-breadcrumbs>
</div>
<div id="content">{{path[path.length - 1 ]}}</div>
<button id="resetButton" ng-click="reset()">Reset</button>
</body>
In line 1 we bind our Path controller to the document body. Every controller has a scope associated with it, which is another core Angular concept. In this example the scope of the Path controller is bound to the body element as well. We refer to the variable path stored in this scope in line 6, and in line 4 we bind the function onPathChange from the same scope to the on-change attribute of the Breadcrumbs comp-breadcrumbs directive we will define a bit later. We also pass to the Breadcrumbs instance in line 3 path from the controller’s scope and define max-entries for it as 5. Finally, in line 7 we specify that the reset function from the scope should be called when resetButton button is clicked.
And here is the code for the controller that adds the mentioned values and functions to its scope:
var app = angular.module('BreadcrumbsDemo', ['Components']);
app.constant('fullPath',
['element1', 'element2', 'element3',
'element4', 'element5', 'element6', 'element7'])
.controller('Path', function Path($scope, fullPath) {
$scope.reset = function() {
$scope.path = fullPath;
};
$scope.onPathChange = function(path) {
$scope.path = path;
};
$scope.reset();
});
In line 6 we inject constant fullPath and $scope into the Path controller. The concept of dependency injection or DI originates from the Java world and there it is used among other things to ensure that we explicitly specify dependencies for every piece of code we use and also that we can easily substitute those dependencies in unit tests with some mocks or stubs. Here, DI also helps to make our JavaScript code more testable and forces us to be more explicit about what dependencies our controllers have. Testability is one of the nicest features of Angular built into it from the very beginning.
Then in lines 7-13 we just set some values in the scope. Just like React Angular will take care of properly rendering and updating the view given the values we put into the scope, also it will register event listeners for us. Here we see how the view update challenge is solved by Angular. But unlike React, we can refer to parent scopes in the markup and also we have to take extra care when propagating value updates from upper scopes downwards the controller/scope hierarchy. On this example it is not quite visible since it has only one controller.
In React as you remember we had a tree of components, nested and composed with each other, in Angular we rather have a tree of controllers and associated scopes nested inside of each other. And controller does not know much about the view part unlike React components.
In fact dealing with those nested scopes and controllers in Angular, updating them in proper order and understanding what scope you are dealing with at each particular moment can be quite confusing and challenging. So at least in this respect React seems to be simpler.
This may already sound a bit complicated, but we are not quite finished with the scopes yet, because now we will take a look at our Breadcrumbs component https://github.com/antivanov/ui-components/blob/master/Angular.js/breadcrumbs/breadcrumbs.js which, like we said before, is just a directive that uses a custom tag name. For this directive there will be two more scopes: one associated with the directive itself and one with the controller of the directive.
var components = angular.module('Components', []);
components.controller('breadcrumbsController', function ($scope) {
function adaptForRendering(path, maxEntries) {
maxEntries = maxEntries || -1;
var hasShortened = false;
var shortenedPath = [];
path.forEach(function(pathPart, idx) {
//Skip path entries in the middle
if ((maxEntries >= 1) && (idx >= maxEntries - 1)
&& (idx < path.length - 1)) {
//Render the dots separator once
if (!hasShortened) {
var tooltipParts = path.slice(maxEntries - 1);
tooltipParts.pop();
shortenedPath.push({
value: '...',
dots: true,
tooltip: tooltipParts.join(' > ')
});
hasShortened = true;
}
return;
}
shortenedPath.push({
value: pathPart,
index: idx
});
});
return shortenedPath;
}
$scope.activatePathPart = function(pathPart) {
$scope.pathSelected(!pathPart.dots ? pathPart.index : -1)
};
$scope.pathSelected = function(idx) {
if (idx < 0) {
return;
}
var newPath = $scope.path.slice(0, idx + 1);
if (newPath.join('/') != $scope.path.join('/')) {
$scope.onChange({
path: newPath
});
}
};
$scope.pathToRender = adaptForRendering($scope.path,
$scope.maxEntries);
$scope.$watchCollection('path', function(path) {
$scope.pathToRender = adaptForRendering(path, $scope.maxEntries);
});
}).directive('compBreadcrumbs', function () {
return {
restrict: 'E',
scope: {
path: '=',
onChange: '&onChange',
maxEntries: '='
},
controller: 'breadcrumbsController',
templateUrl: 'breadcrumbs.tpl.html'
};
});
In lines 60-70 we define a new compBreadcrumbs directive, an instance of which will be created once we use <comp-breadcrumbs> markup in our Angular app. In line 62 with restrict: ‘E’ we specify that the directive can be used only as a custom HTML element. In line 69 we specify the template to be used to generate HTML elements for our directive and in line 68 that controller breadcrumbsController should be used, an instance of which will be created for every instance of our directive.
Lines 63-67 define the isolated scope of the directive and how it is connected with the enclosing scope in which the directive is used. In line 64 we bind path to the path attribute of the directive as it is used in the app markup, and in line 66 we bind maxEntries to the maxEntries attribute. In line 65 we use &onChange so that the onChange function stored in the isolated scope of the directive will be always invoked in the context of the enclosing scope in which the directive is used. This enclosing scope is the scope of the Path controller we saw before.
The behavior of the directive is specified in the controller we use inside it in the lines 3-60.
In lines 38-53 we define the functions that are triggered whenever an individual crumb is activated. When the path should change, like in the earlier examples with Web Components and React, we just call the function provided to the component from the outer scope in lines 49-51. There are quite a few other options to notify the controller from a directive inside it, but we will omit those to keep the discussion of Angular a bit shorter.
In lines 57-59 we specify that Angular should watch the scope for changes in the path and whenever they occur we should update the scope value pathToRender by calling adaptForRendering with path as argument. pathToRender as we will shortly see is referenced in the template of the directive.
In lines 5-36 the crumbs and crumb separators are generated based on the provided maxEntries and path values, but this is not where they are rendered, so the method is called prepareForRendering rather than render. The rendering will happen when the template of the directive will be rendered https://github.com/antivanov/ui-components/blob/master/Angular.js/breadcrumbs/breadcrumbs.tpl.html.
<div class="breadcrumbs">
<span tabindex="{{pathPart.dots ? '' : '0'}}"
ng-class="{'crumb':!pathPart.dots,'crumb-separator':pathPart.dots}"
ng-click="activatePathPart(pathPart)"
ng-keypress="($event.which === 13) && activatePathPart(pathPart)"
ng-attr-title="{{pathPart.tooltip ? pathPart.tooltip : ''}}"
ng-repeat-start="pathPart in pathToRender">{{pathPart.value}}</span>
<span class="crumb-separator"
ng-if="$index < pathToRender.length - 1"
ng-repeat-end>></span>
</div>
In line 7 ng-repeat-start specifies that we iterate over elements pathPart in pathToRender and for each such pathPart we render a span which, depending on whether pathPart.dots is true or false, has either class crumb-separator or just crumb.
In line 4 we say that whenever a crumb is clicked activatePathPart will be called with the corresponding pathPart. Pressing Enter is handled in a similar way in line 5. In line 6 we use ng-attr-title directive on the current crumb or crumb separator if there is a tooltip for the current pathPart.
Note how in this template we can also use directives inside directives in Angular.
To finish our discussion about scopes in regards to the Breadcrumbs component, if you were looking carefully, now we have 3 scopes in total (like we noted before it might get a bit complicated at times).
First scope is the scope of the Path controller in which the component is used. Next scope is the isolated scope of the component’s directive itself. This isolated scope has as its enclosing scope the scope of the Path controller. In addition to that we also use a controller breadcrumbsController inside our directive that has yet another scope associated with it, and this scope has as its parent scope the enclosing scope of the directive. So there are 2 different scopes used in the Breadcrumbs component and one more enclosing scope for the directive. Easy to be confused, so don’t despair and browse the Angular documentation if something is not quite clear about the scopes (most probably it is not if this is the first time you deal with Angular).
Key points, philosophy behind Angular.js
Angular is a framework that suggest its own very opinionated and conceptually distinct way of developing front end for Web apps. It may be quite advantageous to use it if you are looking for something to quickly prototype your app or get up and running fast without getting mired into wiring different libraries and frameworks together.
One significant minus can be that, in a way, Angular just provides a set of tools for you to develop your Web app with, but the most interesting part, how you can use all those tools together, is not always obvious. This seems to slowly change and even the Angular documentation now includes some of the best practices, but you still may constantly find yourself asking the questions like “How should it be done in Angular? What is the best way conceptually?”. And the set of tools that Angular provides may not be the easiest one as well, as it includes quite many of different concepts: scopes, isolated scopes, directives, controllers, nesting, updates, dependency injection, services, factories, constants, etc.
A huge plus is built-in testability, provided for by explicitly specifying which dependencies every controller or directive requires. The view update challenge is also solved nicely, eliminating a whole class of bugs when the view and model in a Web app are out of sync. However, due to not always obvious complex scope nesting and update propagation between different models there can still be some challenges there.
Rendering in Angular is a bit more removed from the controllers as we saw in our simple Breadcrumbs example. The result of this is that the code gets a bit more complicated as there is a bit artificial boundary between the data and markup into which this data is transformed.
Like we noted before, with Angular you may even opt not to use custom directives in your app at all, instead of this building everything with controllers. In a way, this is bad, because it does not encourage you to reuse your code as much as you can, since a Web app is not just a set of modular JavaScript “classes” which controllers essentially are, but rather a set of components that have both the behavior, markup and styles associated with them.
Angular is clearly inspired by Java concepts and brings some of the complexities and patterns associated with enterprise Java development to the JavaScript world. Factories, services, dependency injection – it sounds a lot like a Java app. It might also be a bit contrary to the JavaScript core philosophy of keeping things simple and centered around functions. Instead Angular is centered around class-like objects and patterns and tries to redefine the commonly accepted JavaScript development practices radically. Whether this is a good or a bad thing depends on your personal taste, but some people feel that programming in Angular feels much less like usual programming using JavaScript.
Like with React we can note that the HTML generated by Angular directives plays the role similar to shadow DOM for Web Components, and the tree of Angular components is then analogous to real DOM.
I would encourage you to create reusable components with Angular by using its directives when it is appropriate, this will lead to a better structured app and more code reuse. For some reason this is what many people choose not to do on Angular projects and this seems to be not quite right.
Existing component libraries
There are quite a few existing component libraries, for example https://angular-ui.github.io/bootstrap/ and https://material.angularjs.org/#/
Why not jQuery?
At this point you may be asking: OK, we can create components using all these new libraries, standards and frameworks, but couldn’t we already just do that much earlier with jQuery? In fact, how about jQuery UI https://jqueryui.com/?
To be fair to jQuery we will also provide our Breadcrumbs example implemented as a jQuery plugin and it will actually look just fine. The problems with creating components as jQuery plugins will become visible only when we try to create a few of them and wire them together in a complex app. This is where jQuery plugins miserably fail and do not scale.
If you look at a typical jQuery plugin, it can be used by its client code something like this https://github.com/antivanov/ui-components/blob/master/jQuery/breadcrumbs/breadcrumbs.demo.html:
var $breadcrumbs = $('#breadcrumb-container').breadcrumbs({
'maxEntries': 5,
'path': fullPath
});
Which essentially will just add a few HTML elements and some state and behavior to them. Unfortunately, there is no good way to interact with the app in which we create a component. A possible workaround could be to use custom jQuery events:
$breadcrumbs.on('pathChange', function(event, path) {
$breadcrumbs.trigger('setPath', [path]);
$content.text(path[path.length - 1]);
});
but this is not scalable and isolated enough as we will have to create lots of custom events which will be propagating in our app back and force between different components.
How about creating a nested jQuery plugin and interacting with it from the client app? No, it can be done with some effort, and may not even look that bad, but this is not what jQuery plugins were initially designed for.
jQuery plugin system is geared towards creating isolated rich widgets which extend your app in a patchy manner, but when it comes to interaction between those widgets or organizing them together into a whole we immediately run into difficulties, so the jQuery approach does not scale in this sense.
jQuery plugins are just a distant ancestor of Web components. They made their contribution in the past, encouraged creating some useful widgets in their time but are completely unsuitable for modern large Web apps because of the scalability issues.
You can still find things like jQuery UI https://jqueryui.com/ quite useful for some small Web apps and this will probably remain their niche. In this case you just need to patch your page a bit with a couple of jQuery plugins: add a bit of interactivity or to use a few nicely looking widgets. But if you wish to create a full-fledged app with dozens of complex custom components interacting with each other and the rest of the app, then you need something else.
As promised, here is the Breadcrumbs example using jQuery plugin system, it looks a bit like the widgets you can find in jQuery UI and other libraries exposing their widgets as jQuery plugins:
(function ($) {
$.fn.breadcrumbs = function(options) {
var self = this;
options = $.extend({
maxEntries: -1,
path: []
}, options);
var maxEntries = options.maxEntries;
var path = options.path;
var $container = $('<div></div>').attr('class', 'breadcrumbs')
.appendTo(self);
$container.on('click', '.crumb', function(event) {
activateCrumb(self, $(event.target));
}).on('keypress', '.crumb', function(event) {
if (event.which == 13) {
activateCrumb(self, $(event.target));
}
});
renderPath(this, path);
this.on('setPath', function(event, newPath) {
path = newPath;
renderPath(this, path);
});
function activateCrumb(self, $crumb) {
var idx = parseInt($crumb.attr('idx'));
var newPath = path.slice(0, idx + 1);
if (newPath.join('/') != path.join('/')) {
self.trigger('pathChange', [newPath]);
}
}
function renderPath(self, path) {
var renderedDotsSeparator = false;
$container.empty();
path.forEach(function(pathPart, idx) {
//Skip path entries in the middle
if ((maxEntries >= 1) && (idx >= maxEntries - 1)
&& (idx < path.length - 1)) {
//Render the dots separator once
if (!renderedDotsSeparator) {
createDotsSeparator(path, maxEntries)
.appendTo($container);
createCrumbSeparator().appendTo($container);
renderedDotsSeparator = true;
}
return;
}
createCrumb(pathPart, idx).appendTo($container);
if (idx != path.length - 1) {
createCrumbSeparator().appendTo($container);
}
});
}
function createDotsSeparator(path, maxEntries) {
var $crumbSeparator = $('<span></span>');
var tooltipParts = path.slice(maxEntries - 1);
tooltipParts.pop();
var tooltip = tooltipParts.join(' > ');
return $crumbSeparator.attr('class', 'crumb-separator')
.attr('title', tooltip).text('...');
}
function createCrumb(pathPart, idx) {
return $('<span></span>').attr('class', 'crumb')
.attr('tabindex', '0').attr('idx', idx).text(pathPart);
}
function createCrumbSeparator() {
return $('<span></span>').attr('class', 'crumb-separator')
.text('>');
}
return this;
};
}(jQuery));
The code should be more or less self-evident if you are familiar with jQuery, otherwise it is not worth spending more time on covering it as, like we discussed, jQuery is not relevant for our purposes of creating reusable components in large modern Web apps.
Other options
There are still quite a few other options available if you want to create reusable components.
For example, we can mention Ember.js http://guides.emberjs.com/v1.10.0/cookbook/helpers_and_components/creating_reusable_social_share_buttons/.
Another option is Ample SDK http://www.amplesdk.com/tutorials/edg/element/. In fact, Ample SDK back in 2011 was for me the introduction to modern reusable components.
Knockout.js http://knockoutjs.com/documentation/component-overview.html also allows to create custom elements.
The list continues, however, we will not cover the remaining frameworks and libraries in the present article since the ones we already discussed should already give a good feel and exhibit some of the ideas behind component based development.
Different Mental Model
In order to use components in ours apps efficiently, no matter what particular technology we choose to use, a certain change in the way we think about the app structure is required.
React has a good introduction into this new way of thinking “Thinking in React” https://facebook.github.io/react/docs/thinking-in-react.html which could have as well been titled as “Thinking in Components” and is not that React-specific as it might seem at the first glance.
The basic idea is to decompose the structure of your app into simple parts and see how the application is composed from them.
For example for a simple e-mail client:
- App
- Header
- User menu
- View profile menu item
- Logout menu item
- Sidebar
- Content
- Footer
This rough breakdown gives a general idea what components our application can be composed from.
If not using React you may decide to implement as components only some of the elements of the interface and follow a more traditional approach elsewhere. Good candidates to be components could be, for example, User menu or Folder. You can also decide to have your own List component, based on which the Email List will be implemented.
If it so happens that besides the e-mail client we also need to build, say, a social network with similar interface and controls, we can potentially reuse quite a lot of code by using the already created List, Folder and User menu components.
Like we mentioned before, components are a bit like functions or classes. Splitting your app into small reusable functions or classes does not mean that all of them will be ultimately reused somewhere, but it certainly gives your app a better structure and leads to better maintainability and code reuse. This is precisely what happens here as well, once we analyze and decompose our app structure and create the app out of components.
So it pays off to think in components just like it pays off to think in terms of reusable functions and classes, and, for example, React deems it so important that everything is by default a component.
Putting It All Together
Now it is time to do a brief comparison of different approaches to componentization that were covered in this article. We will also recap some of the key points already occasionally made earlier and maybe a bit hard to spot among all the technical details. We cannot directly compare, for example, Web Components and React since it will be a bit like comparing apples with oranges, instead we will try to give a feeling how all those technologies fit together and what is their relationship to each other.
We started first with Web Components, a set of standards that allows to define and use components in your Web applications and all the familiar standard APIs will just work out of the box. Web Components are not yet widely supported by different browsers and still have a lot of space to mature. Another thing to consider is that the standards are quite low-level and generic in order to give the maximum amount of freedome to client developers and not to overburden browser developers. Then in real life you will probably have to use something on top of Web Components, as this is just a low-level integration mechanism which allows you to plug in your own custom elements into existing HTML vocabulary.
One such higher level library you may choose to use is Polymer. It brings support of Web Components standards to different browsers, adheres to them quite closely, and in addition provides a few useful features of its own, such as more advanced templating and many available components that you can extend. However, Polymer may still not be high-level enough as it still deals with many low-level mechanisms of Web Components standards. To Web Components Polymer is a bit like jQuery was to DOM APIs in its beginning: more syntactic sugar and making sure that everything works consistently among different browsers. You can also easily choose to use Polymer with your favorite framework or other libraries and for some people this may be just what they are looking for.
While Web Components standards are still being developed and adopted by browsers in response to the genuine need for componentization in many modern apps, there sprung up quite a few alternatives which share a very similar philosophy but have a bit different implementation details. Many of those alternatives would construct a separate tree of their own components which they would then render into HTML. We covered probably two most prominent and promising representatives: Angular and React.
React is a library that deals with the view part in the MVC architecture of Web apps. It is centered around components, a tree of which is generated from the supplied data and then is transformed into HTML. The transformation is declarative and functional-like. The resulting DOM seems to a client developer almost as if it were immutable, when in fact React just cleverly hides under the hood some smart techniques for updating only the parts of DOM which really need to be updated. React is conceptually simple and powerful, and you can choose to use it together with the Flux architecture which adds the missing application data flow dimension to your app in a manner consistent with the React philosophy.
Angular appeared before React and is a full-fledged framework. Support for creating components is just one of its many features, unfortunately quite often neglected and not well understood. Nonetheless Angular also allows to create reusable components, although the API is a bit more involved and dealing with different scopes can quickly become a pain. If you are using Angular on your projects, you should consider giving more attention to creating components when appropriate. It seems that now there is some movement in the Angular world to emphasize the role of components (directives) more and even integrate Angular with Web Components, for example, a couple of articles to this extent https://pascalprecht.github.io/2014/10/25/integrating-web-components-with-angularjs/ http://teropa.info/blog/2014/10/24/how-ive-improved-my-angular-apps-by-banning-ng-controller.html
Being non-standard, both React and Angular lock you in into using them, probably React less so since it deals only with the view part and can be used more easily with other libraries. This may be an important consideration for some, but it is quite likely that React and Angular may also choose to be interoperable with Web Components in the future.
In the coming time I would expect that the alternative solutions start to use the Web Components spec or Polymer, first, to leverage the existing standard technology instead of inventing their own workarounds on top of old Web standards and, second, to provide more interoperability with other frameworks and libraries.
It is a bit sad that there are now separate implementations of the same components for all the different frameworks, just think about all that development effort that goes into supporting parallel implementations and the overhead of learning different APIs and approaches. On the other hand this is how things are often done in the JavaScript world and to a certaint extent this may still be a useful overhead: the new much needed features are first pioneered by a few cutting-edge frameworks or libraries, then some standards inspired by them appear, and then there is a certain degree of convergence among those frameworks and libraries to the new standards. But how the things will unfold still remains to be seen in the next few years.
In most cases, at the present moment, I would probably recommend using either React or Angular depending on your taste. But no matter what framework or library you decide to use, do not miss out on leveraging the power of componentization.
Summary
We will close off this article with a bit philosophical discussion. As was noted in the famous book “Structure and Interpretation of Computer Programs” https://mitpress.mit.edu/sicp/full-text/sicp/book/node5.html
A powerful programming language is more than just a means for instructing a computer to perform tasks. The language also serves as a framework within which we organize our ideas about processes. Thus, when we describe a language, we should pay particular attention to the means that the language provides for combining simple ideas to form more complex ideas. Every powerful language has three mechanisms for accomplishing this:
- primitive expressions, which represent the simplest entities the language is concerned with,
-
means of combination, by which compound elements are built from simpler ones, and
-
means of abstraction, by which compound elements can be named and manipulated as units.
In our case, creating specific components when building a Web app is essentially just creating a form of language in which our application can be easily described and built like we just did above with the e-mail client example. The parallels are clear:
- primitive expressions – predefined HTML elements and their behavior
- means of combination – being able to put HTML elements together into a DOM tree and create an HTML document, and maybe also define some additional behavior for those elements by using JavaScript
- means of abstraction – ability to encapsulate the HTML elements and associated behavior into new HTML elements, creating new abstractions – components
The first two primitive expression and means of combination are available to Web developers for a long time already from the very beginning. The last one means of abstraction is what Web Components and the frameworks and libraries sharing its spirit try to provide only in the last few years. Having the ability to create components allows to build more powerful abstractions when building Web apps and ultimately enables building modern complex Web apps faster and easier.
Even when you talk about Web apps with other people such as designers or users, instead of talking about things such as divs or spans or sections you tend to talk about searchboxes, grids, menus, tabs, shopping carts, bookings, etc. So if you are already using components in your own language, why then not just use them in code, so that the code is closer to how we reason about the app to begin with?
The article turned out to be a bit lengthy as we had to cover quite many things and somewhat different approaches to solving the same problem, but hopefully it was still useful and you may now try to give reusable components a chance on your next project, focus more on them in your development practices and use the related features of your favorite framework or library more confidently and with understanding of the philosophy and ideas behind them.
Links